Scanneur
Scanner le livre Vocabulaire thématique, pour prendre tous les mots
et en faire une nouvelle base de donnée (environ 4 600 mots) pour mon quiz d'anglais.

L'idée :
Pour enrichir ma base de données avec du vocabulaire anglais plus technique destiné à mon quiz,
je me suis demandé comment extraire efficacement les mots à partir d'un livre spécialisé.C'est ainsi qu'est née l'idée de développer un script capable de scanner de traiter les images du livre et d'en extraire automatiquement le texte.
Partie tecnhique :
Pour ce projet en Python, j'ai utilisé plusieurs outils complémentaires :- OpenCV pour le traitement des images scannées (ajustement, redimensionnement, netteté, etc.)
- Tesseract OCR pour la reconnaissance optique des caractères et l'extraction automatique du texte à partir des pages
- Une conversion vers le format .md (Markdown) afin de faciliter l'organisation et l'import dans ma base de données
- Enfin, j'ai utilisé le module re (expressions régulières) pour nettoyer les textes, en supprimant ou remplaçant certains caractères non désirés.
Cette chaîne de traitement m'a permis d'automatiser une grande partie du processus d'acquisition de vocabulaire technique depuis l'image scannée.
Les améliorations à ajouter :
Dans le futur, les mots extraits pourront être ajoutés au quiz d'anglais, avec la possibilité de les lier à une ou plusieurs images.L'idée serait de permettre à l'utilisateur de créer ses propres catégories personnalisées, basées sur des documents qu'il aura lui-même fournis (comme des livres, manuels ou supports spécialisés).
Cela offrirait à chacun la possibilité de constituer un vocabulaire sur mesure, en fonction de ses besoins et de ses intérêts, rendant ainsi l'apprentissage plus pertinent et motivant.
Pour résumer :
Le projet est globalement réussi et fonctionnel.Il reste encore quelques détails à peaufiner, notamment pour améliorer la reconnaissance des mots, affiner le nettoyage du texte, et rendre le système plus robuste et adaptable à différents types de documents.
Résultat :

1ère page du livre
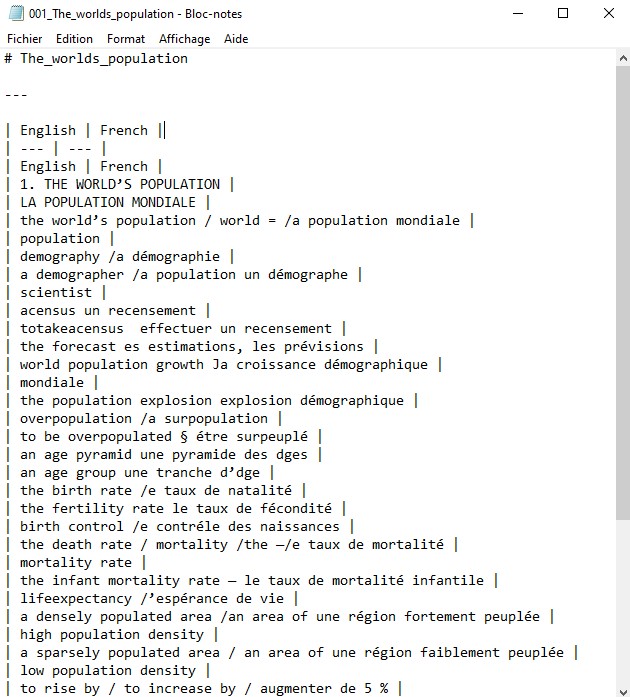
Transformation de l'image en texte
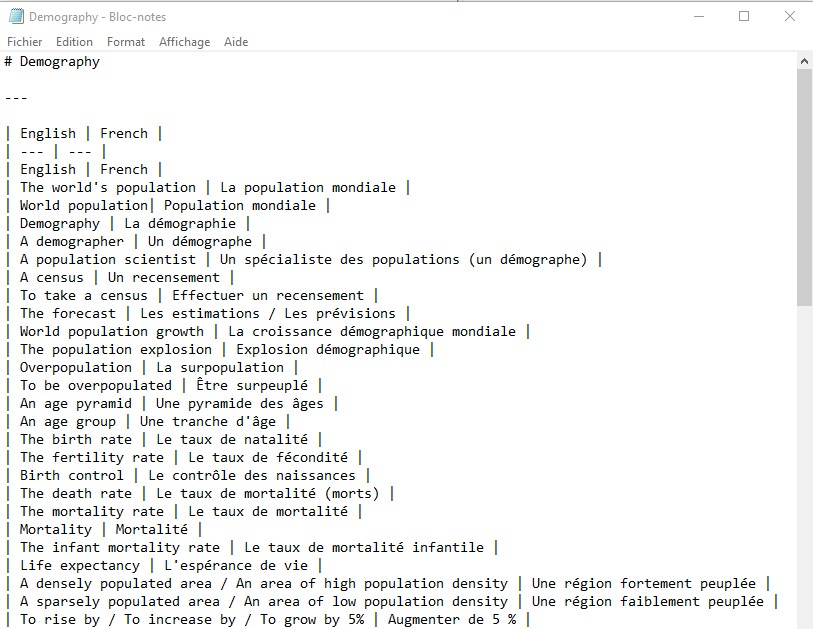
Résultat final après la mise au propre par l'algorithme
Mon objectif :
Cette fonctionnalité pourrait être intégrée directement dans mon quiz d'anglais,
offrant aux utilisateurs la possibilité de personnaliser leur apprentissage.Cela me permettrait aussi d'enrichir ma base de données d'origine avec du vocabulaire varié.